
百万级指标监控怎么搞?Prometheus 扛不住了,我转身换上了 VictoriaMetrics
很多做运维的朋友都被 Prometheus 的存储问题折磨过:数据量一上来,内存溢出(OOM)像家常便饭,扩磁盘又要停机,查半年前的曲线能卡到浏览器崩溃。
上周我把生产环境的监控全量切到了 VictoriaMetrics(简称 VM)集群版。今天把这套“高可用、读写分离、无限扩容”的部署方案分享出来,全是实操干货。
为什么要搞集群版?
Prometheus 好用,但它是个“巨石”架构,存、取、写全在一个 Pod 里。VM 集群版最聪明的地方在于它把这些活儿拆给了四个角色:
1. 采集端:vmagent(轻量且强悍)
- 资源极低:内存消耗仅为 Prometheus 的 1/5 左右。
- 磁盘备份:通过
-remoteWrite.tmpDataPath参数,在后端故障时可暂存数 GB 的数据。
2. 写入端:vminsert(流量调度)
vminsert 是无状态的。它接收来自 vmagent 的数据,并计算一致性哈希,决定将数据路由到哪一个 vmstorage。
- 多租户入口:URL 中的
accountID(如/insert/0/)在这里被处理,实现逻辑上的数据隔离。
3. 存储端:vmstorage(数据仓库)
这是集群中唯一的有状态组件(StatefulSet)。
- 数据分片:它不感知其他 storage 节点,只负责存好分配给自己的那份数据。
- 高性能压缩:VM 采用了自研的存储格式,磁盘空间占用通常只有 Prometheus 的 1/7。
4. 查询端:vmselect(聚合计算)
它是查询的入口。当 Grafana 发起请求时,vmselect 会并行的向所有 vmstorage 节点请求数据,然后在内存中进行聚合计算并返回结果。
部署实战:Operator 模式
在 K8s 里,我建议直接上 VictoriaMetrics Operator,别去手写那些复杂的 Deployment。
1. 搞定 values.yaml
安装官方 Chart 时,有一个大坑:一定要显式关掉默认的单机模式(vmsingle),否则 Operator 会因为配置冲突导致 Pod 疯狂报错。
# 核心 values.yaml
vmsingle:
enabled: false # 坑1:必须关掉,否则无法开启集群模式
vmcluster:
enabled: true
spec:
retentionPeriod: "30d" # 历史数据留存时间
replicationFactor: 2 # 生产环境起码2副本,数据更稳
#retentionPeriod: "1" # 数据保留 1 个月
vmstorage:
replicaCount: 2
storage:
volumeClaimTemplates:
spec:
storageClassName: "ssd-storage" # 坑2:一定要用 SSD,IO 并发跟不上查图会卡
resources:
requests:
storage: 100Gi
vminsert:
replicaCount: 2 # 写入入口,无状态
vmselect:
replicaCount: 2 # 查询入口,无状态
2. 执行安装
helm repo add vm https://victoriametrics.github.io/helm-charts/
helm repo update
helm install vms vm/victoria-metrics-k8s-stack -f values.yaml -n monitoring --create-namespace
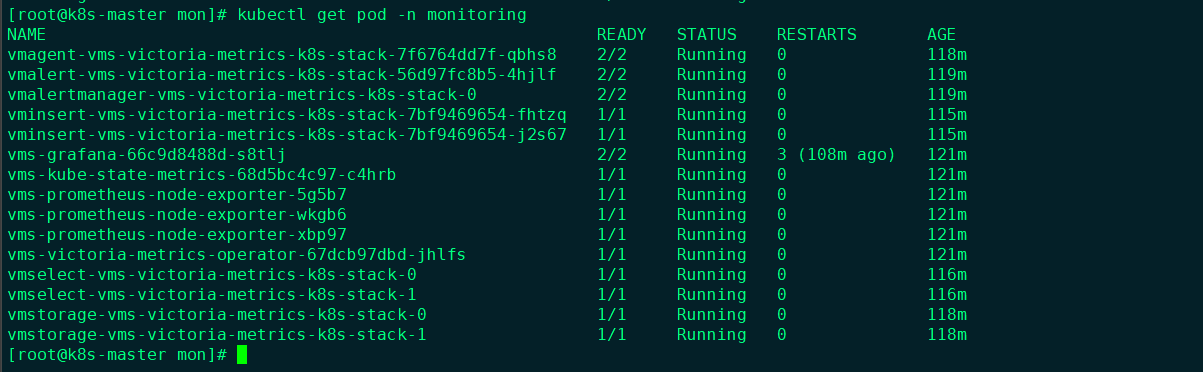
进阶:如何访问那些“打不开”的 UI?
默认部署完,你会发现不管是 vmagent 还是 vmselect 的 UI 都进不去,因为它们默认是集群内访问。
别去改原生的 Service,那会被 Operator 自动重置回来。最土但最稳的办法是:自己手写两个 NodePort Service。
查“特务”状态(vmagent)
想看哪些 Pod 监控断了?直接访问 http://节点IP:30429/targets。
apiVersion: v1
kind: Service
metadata:
name: vmagent-nodeport
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 8429
nodePort: 30429
selector:
app.kubernetes.io/name: vmagent
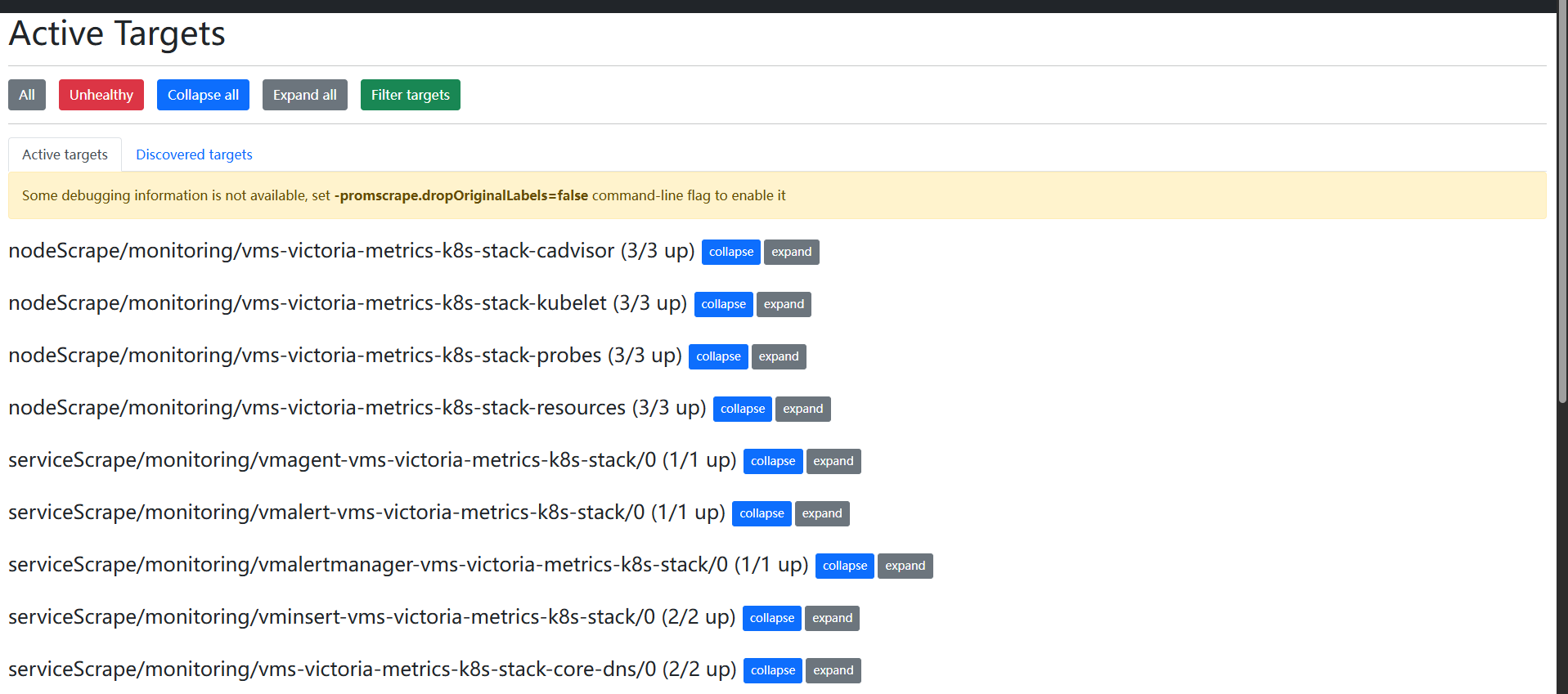
查“仓库”数据(vmselect)
想直接写语句查后端原始数据?访问 http://节点IP:30481/select/0/vmui/。这里的 VMUI 界面自带分析器,查大批量指标特别爽。
apiVersion: v1
kind: Service
metadata:
name: vmselect-nodeport
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 8481
nodePort: 30481
selector:
app.kubernetes.io/name: vmselect
硬核科普:为什么存储不够了加个 Pod 就能行?
很多兄弟理解不了:数据散在不同的 Pod 里,存储怎么扩容?
这就是 VM 集群版最硬核的地方。vminsert 会根据标签把指标“哈希”分配。比如你原本有 2 个 vmstorage(仓库 A 和 B),当存储快爆了,你只需把副本数改成 4。
新的仓库 C 和 D 瞬间上线,后续产生的新数据就会被匀给 C 和 D。而当你查询时,vmselect 就像个管家,它会向 A、B、C、D 同时发起广播,把分散的数据瞬间拼成一条完整的曲线返给你。对你来说,容量变大了,查图却没感知,这就是水平扩容的魅力。
生产环境的几点“私房菜”
- Grafana 配置:在 Grafana 选 Prometheus 数据源,URL 填内部 Service 地址:
http://vmselect-vms-victoria-metrics-k8s-stack:8481/select/0/prometheus/。记得中间那个 /0/ 别漏了,那是默认租户。 - 多租户隔离:如果你们公司有不同的业务线,可以给不同的
vmagent设置不同的租户 ID(比如/insert/1/)。数据在底层是逻辑隔离的,互不干扰,非常安全。 - 数据冷热分离:VM 压缩率极高,1 个指标通常只占不到 1 字节。如果磁盘压力大,记得去查一下哪些指标的 Label 太多(基数爆炸),该 Relabel 过滤的千万别手软。
如果你也在做大规模监控,这套方案绝对值得你一试。评论区欢迎交流踩坑心得!
